Inside the Qt 4 Containers
Qt 4 provides a new set of container classes that are available to Qt applications in addition to the STL containers. In this article, we will see how they are represented in memory. Knowing how containers work internally makes it easier to choose the right container for the right circumstance. Just be aware that some of the classes mentioned here are internal and should not be used directly.
Sequential Containers
QVector
QVector
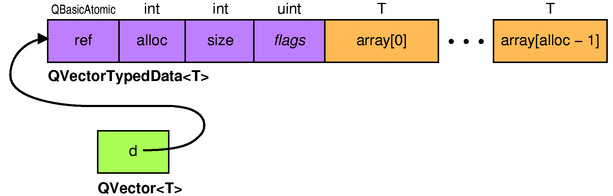
Like nearly all of Qt's containers and most other value classes
(including QString),
QVector
The QBasicAtomic class, used to store the reference count, is an integer type that supports atomic (thread-safe) increment and decrement operations, ensuring that implicit sharing works across threads. QBasicAtomic is internal and implemented in assembly language on the different architectures supported by Qt.
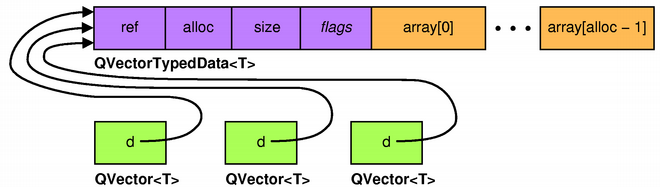
The diagram below depicts the situation in memory when we take two
extra copies of an existing
QVector
To avoid reallocating the data every time the vector grows,
QVector
- If T is a movable type (a data type that can safely be
moved around in memory using memcpy() or memmove(), such as
the C++ primitive types and Qt's implicitly shared classes),
QVector
uses realloc() to grow by increments of 4096 bytes. This makes sense because modern operating systems don't copy the entire data when reallocating a buffer; the physical memory pages are simply reordered, and only the data on the first and last pages need to be copied. - For non-movable data types,
QVector
grows by 50 per cent increments, ensuring that repeatedly calling append() results in amortized O(n) behavior rather than O(n–Ü).
The distinction between movable and non-movable types is also used to
speed up insertions in the middle of the vector. When such an
insertion takes place, the elements that come after the point of
insertion must be moved one position further. If T is a movable
type, this is achieved using memmove(); otherwise,
QVector
If you use QVector
class MyClass { ... private: MyClassPrivateData *data; }; Q_DECLARE_TYPEINFO(MyClass, Q_MOVABLE_TYPE);
The type information provided by Q_DECLARE_TYPEINFO() is used by
other containers as well, notably
QList
class MyClass { ... private: int x; int y; }; Q_DECLARE_TYPEINFO(MyClass, Q_PRIMITIVE_TYPE);
If T is a primitive type,
QVector
QList
Unlike its predecessors
QPtrList
Depending on the type T,
QList
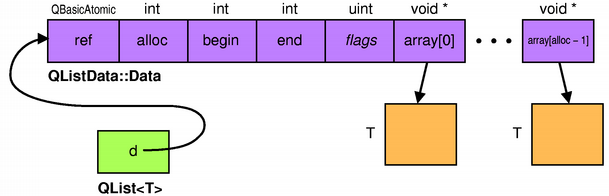
This organization makes insertions and removals in the middle faster
than what QVector
Like QVector
- A common list operation such as prepending an item or removing
the first item usually takes constant time, because the buffer can grow
backwards. This is the reason why
QQueue
is based on QList , whereas QStack is based on QVector . - In the general case of an insertion at position k,
QList
can choose between moving the first k items by one position to the left and moving the last n - k items by one position to the right. If k is 10 and n is 2000, it makes more sense to move 10 items to the left than 1990 to the right.
Exceptionally, in the special case where type T has the size of a
pointer and can be moved in memory using memcpy() or
memmove(), QList
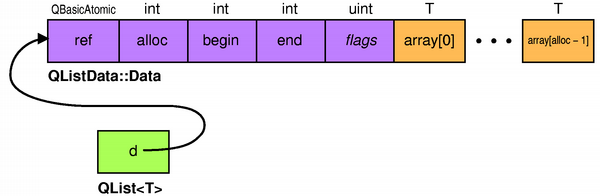
This optimization covers several very common types, including virtually all pointers types, most of Qt's implicitly shared classes (including QString), as well as int on 32-bit platforms.
QLinkedList
QLinkedList
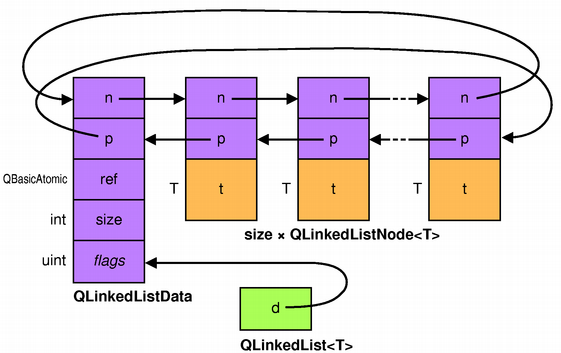
Be aware that although insertions are guaranteed to occur in constant
time, QLinkedList
Now that we understand how Qt's main sequential containers are represented in memory, we can reread the guidelines that appear in Qt's reference documentation and check that they square with reality:
- For most purposes, QList is the right class to use. Its index-based API is more convenient than QLinkedList's iterator-based API, and it is usually faster than QVector because of the way it stores its items in memory. It also expands to less code in your executable.
- If you need a real linked list, with guarantees of constant time insertions in the middle of the list and iterators to items rather than indexes, use QLinkedList.
- If you want the items to occupy adjacent memory positions, use QVector.
It turns out the guidelines are sensible, although they don't mention that for pointer types and implicitly shared types like QString, the main difference between QList and QVector is that QList provides faster insertions and removals in the first half of the container.
QVarLengthArray
Unlike the other sequential containers in Qt,
QVarLengthArray

If size is larger than Prealloc,
QVarLengthArray
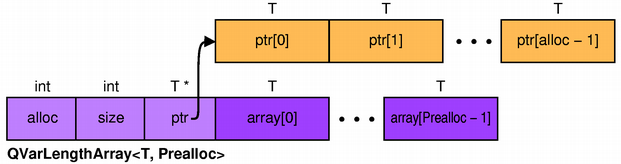
QVarLengthArray
Associative Containers
QMap
QMap
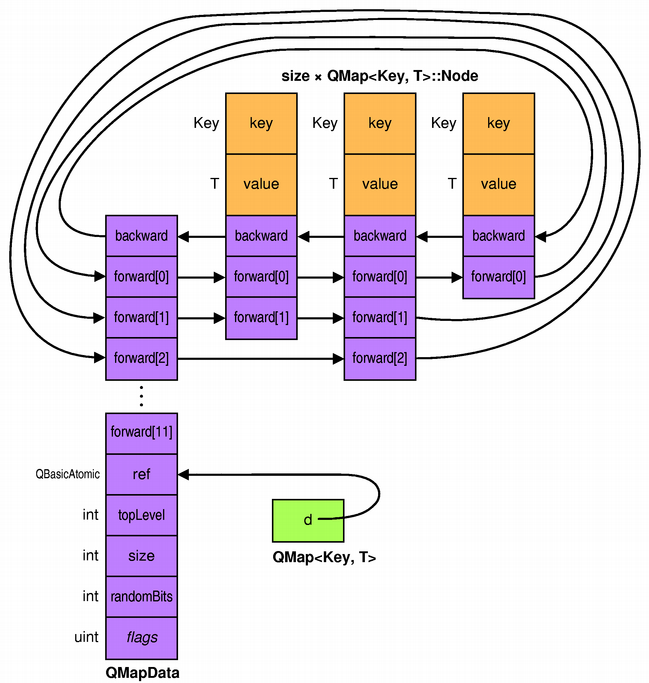
Skip-lists are a generalization of linked lists, where each node has one, two, three, or more forward pointers; forward[0] points to the next node, forward[1] (if present) points to the next node that has a forward[1] field, and so on. The backward pointer in each node is used to iterate backwards.
To lookup a key, QMap starts by advancing as far as possible using the chain of forward[11] pointers, then it continues with forward[10], forward[9], ..., forward[0]. Since items are sorted by key, by comparing the current node's key with the key to find, QMap can tell whether it has gone too far or not.
For example, to find item G in the skip-list depicted below, we follow QMapData's forward[2] link to D. Continuing with forward[2] would lead us to H, which is too far; therefore we follow forward[1], which brings us to F. From there, forward[1] leads to H, which is too far, so we follow forward[0] and reach G.
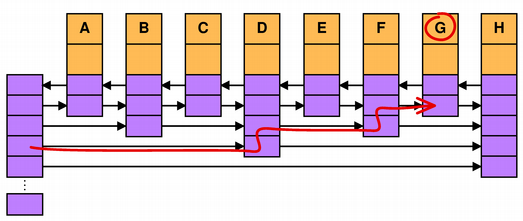
In an ideal world, skip-lists would always be perfectly balanced as shown above, in a nice 1-2-1-3-1-2-1-4-1-2-1-3... pattern that is reminiscent of the notches on a ruler. In practice, this rarely happens, because items can be inserted in any order. But there are circumstances where this utopian scenario occurs: when we read a QMap from a QDataStream, and when a deep copy of a QMap is taken.
QHash
Hash tables usually provide faster lookups than map. For that reason, Qt offers QHash as an (unsorted) alternative to QMap. The two classes have almost identical APIs, but the requirements on the Key type are different:
- For QMap, the Key type must support operator<(), which specifies a total order (i.e., if neither x < y nor y < x, then x == y).
- For QHash, the Key type must support operator==() as well as qHash(), a global hash function.
Qt provides implementations of qHash() for C++ primitive numeric types, pointer types, QChar, QByteArray, and QString. For example, here is the qHash() overload that handles QStrings:
uint qHash(const QString &key) { const QChar *ptr = key.unicode(); int n = key.size(); uint h = 0; uint g; while (n--) { h = (h << 4) + (ptr++)->unicode(); if ((g = (h & 0xf0000000)) != 0) h ^= g >> 23; h &= ~g; } return h; }
You can use custom types as Keys in a QHash, as long as you provide a custom qHash() implementation. Your implementation must meet the requirement that if x == y, then qHash(x) == qHash(y).
In addition, to ensure maximum performance, the hash function should be designed in such a way that if x != y, then it's highly likely that qHash(x) != qHash(y). Thus, a trivial implementation such as
uint qHash(const MyClass & /* key */) { return 0; }
Inside QHash, each item is stored in a separate node and the nodes are linked together inside a bucket. The hash function is used to determine in which bucket to put an item. More precisely, an item with key k is stored in buckets[qHash(k) % numBuckets].
With the trivial qHash() implementation above, all the items would end up in bucket 0, creating a long chain of items and resulting in very slow (linear) lookups. With a suitable qHash() implementation, the items are more likely to be distributed evenly among the buckets, and lookups occur in constant time on average (which beats QMap's O(log n) behavior).
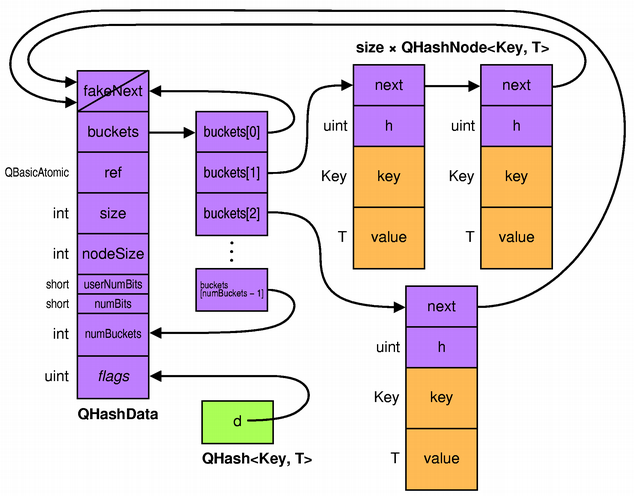
To minimize the number of collisions, the bucket table always has a prime number of entries. As the QHash grows, so does the number of buckets. If you know in advance approximately how many items you will store in the QHash, you can call reserve() to set the number of buckets, avoiding the continual resizing of the bucket table.
If the Key type is int or uint, the hash function used is the identity function (i.e., qHash(x) == x). In addition, QHash is smart enough not to store the key in that case, since it is identical to the hash value, saving four bytes per node.
When traversing a QHash using an iterator, the iterator points directly at a node. Calling ++ on the iterator advances the iterator to the next node in the same bucket, using the current node's next pointer. If the current node is the last node in the bucket (as is typically the case when we use a suitable hash function), next points to the QHashData object. This object is recognizable by its first field (fakeNext), which is always a null pointer. From there, the iterator continues iterating in the next bucket.
QMultiMap
Conclusion
Whereas STL's containers are optimized for raw speed, Qt's container classes have been carefully designed to provide convenience, minimal memory usage, and minimal code expansion. For example, Qt's containers are implicitly shared, meaning that they can be passed around as values without forcing a deep copy to occur. Also, sizeof(QXxx) == sizeof(void *) for any Qt container, and no memory allocation takes place for empty containers.
Qt's containers fully take advantage of partial template instantiation to provide different implementations depending on the data type that is stored. Qt solves the code expansion issue that arises in conjunction with C++ templates by putting most of the container code in non-template internal classes such as QListData and QMapData, making Qt's containers particularly well suited for embedded programming.
Now that you know how the Qt 4 containers work under the hood, you can take advantage of this knowledge to write code that does the proper memory/space tradeoffs based on your needs.
| Copyright © 2006 Trolltech | Trademarks |